Brain Tumor Detection Using MRI and Deep Learning
This project showcases a modular ML pipeline for classifying brain tumors from MRI images using ResNet18.
Brain tumors represent a diverse group of intracranial neoplasms that pose a significant threat to neurological function and survival. Among the most commonly diagnosed types are gliomas, meningiomas, and pituitary adenomas. Gliomas originate from glial cells and span a biological and prognostic spectrum from lower-grade, IDH-mutant diffuse gliomas to highly aggressive glioblastoma (WHO grade 4) (Louis et al., 2021). Meningiomas arise from the meninges; while many are benign (WHO grade 1), their extra-axial location can lead to mass effect and cranial nerve deficits, and atypical/anaplastic variants can recur (Goldbrunner et al., 2021). Pituitary adenomas (now termed “pituitary neuroendocrine tumors”) are common sellar lesions that can be hormonally active or nonfunctioning; macroadenomas may compress the optic chiasm and adjacent structures (Melmed, 2020).
Globally, primary brain and CNS tumors account for hundreds of thousands of incident cases annually, with glioblastoma carrying a 5-year survival rate below 5% despite multimodal therapy (Ostrom et al., 2022; Weller et al., 2015). Early and accurate characterization is therefore essential to guide treatment pathways (surgery, radiotherapy, systemic therapy) and follow-up strategies. Magnetic resonance imaging (MRI) remains the cornerstone for non-invasive assessment owing to its soft-tissue contrast and multiparametric capability. Typical diagnostic protocols include T1-weighted (pre- and post-contrast), T2-weighted, and FLAIR sequences, often complemented by diffusion and perfusion imaging to capture microstructural and hemodynamic features that correlate with cellularity and angiogenesis (Ellingson et al., 2015).
Distinguishing between tumor types can be challenging because imaging phenotypes overlap: infiltrative gliomas may enhance heterogeneously or present as non-enhancing FLAIR hyperintensities; meningiomas often display a “dural tail” and hyperostosis but can mimic intra-axial masses when deeply seated; and pituitary adenomas vary in size and enhancement patterns, especially after prior therapy. Inter-observer variability and differences in acquisition protocols further complicate interpretation (Gevaert et al., 2016). These factors motivate robust computational tools that can standardize and support the radiological workflow.
Over the past decade, deep learning—particularly convolutional neural networks (CNNs)—has achieved strong performance in neuro-oncology tasks, including lesion segmentation (e.g., the BraTS challenge) and tumor classification (Menze et al., 2015; Bakas et al., 2018; Lundervold & Lundervold, 2019). Nevertheless, clinical translation requires careful attention to data quality, external validity, and interpretability. Dataset leakage, label noise, and duplicate images can artifactually inflate performance, while lack of model explanation may hinder trust and safe deployment (Roberts et al., 2021; Oakden-Rayner, 2020).
This project presents a comprehensive, modular pipeline for automated classification of brain MRI into four
categories—glioma_tumor, meningioma_tumor, pituitary_tumor, and no_tumor—using a curated public dataset
(sartajbhuvaji/brain-tumor-classification-mri). The workflow emphasizes rigorous data
validation (file integrity checks, duplicate and cross-class duplicate removal), standardized preprocessing
(resize/pad to 224×224 with intensity normalization), stratified splitting, and training a
ResNet18 classifier. To support transparency, we employ Grad-CAM visual explanations to
verify that predictions align with tumor-relevant anatomy. The goal is an interpretable and reproducible
framework that (i) quantifies the impact of curation on downstream performance and (ii) serves as a
principled foundation for future diagnostic decision-support systems in neuro-oncology.
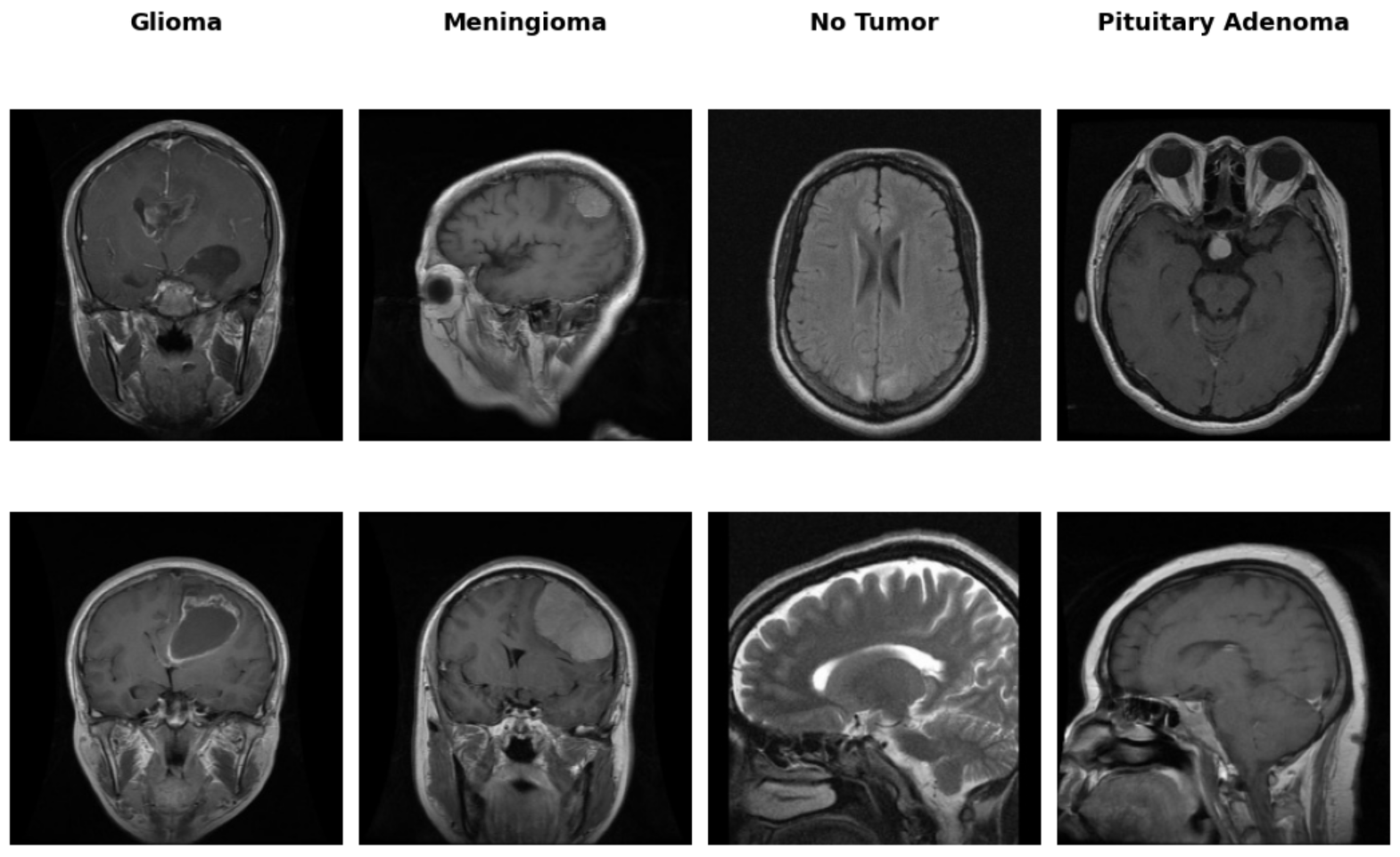
The MRI dataset used in this project contains axial, sagittal, and coronal cross-sectional views of brain scans associated with three major tumor types: glioma, meningioma, and pituitary adenoma. A visual inspection of the dataset reveals significant heterogeneity in scan orientation, contrast, and anatomical presentation—factors that are common in real-world clinical imaging repositories (Figure 1). While the source images were ultimately resized and padded to a uniform 224×224 format for model input compatibility, the original dimensions varied considerably. This non-uniformity highlighted the need for preprocessing to ensure consistent spatial input structure for convolutional neural networks, without compromising the integrity of anatomical detail.
Figure 1: Representative MRI slices across tumor classes showing variation in cross-section and anatomical coverage.
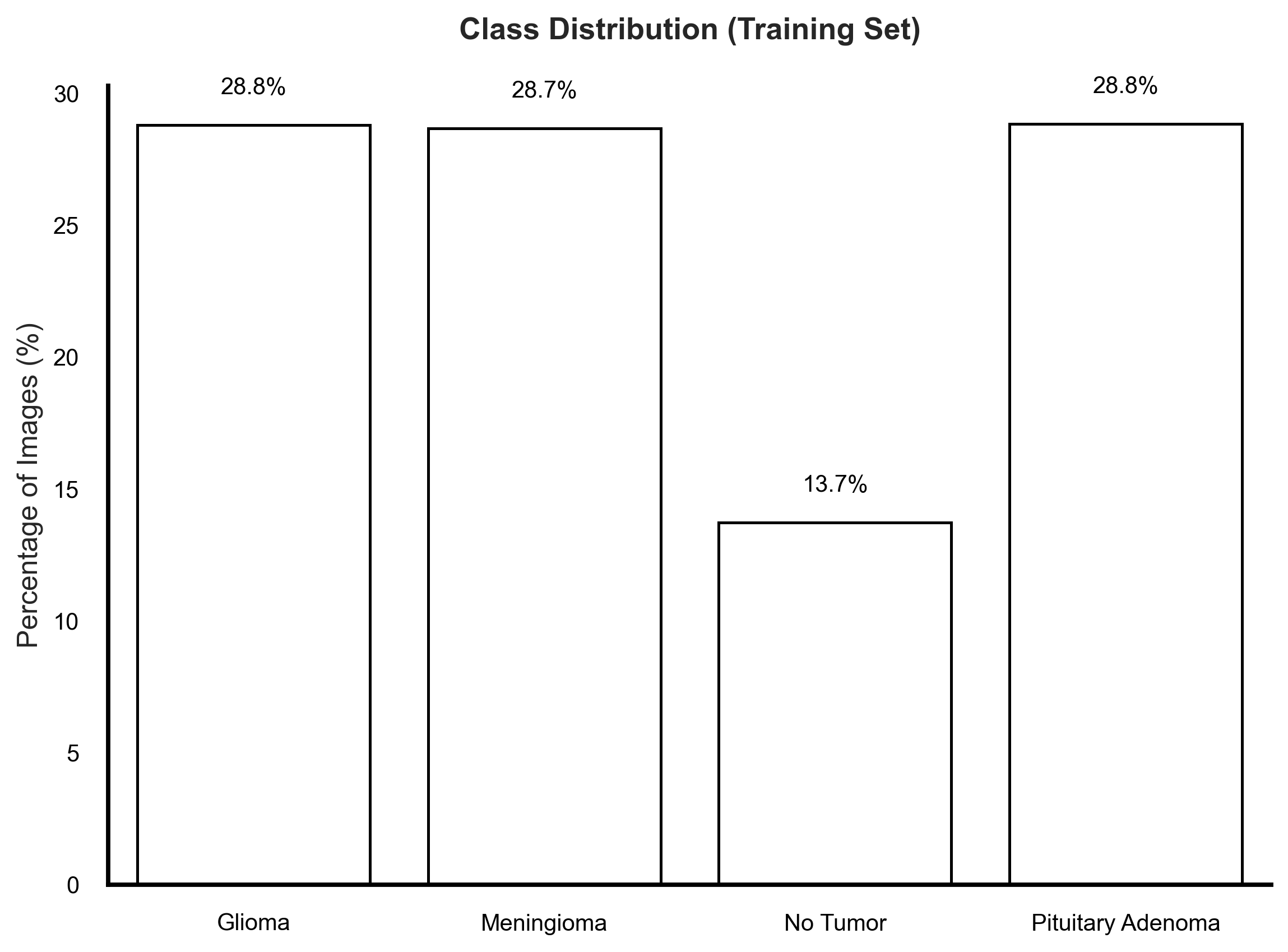
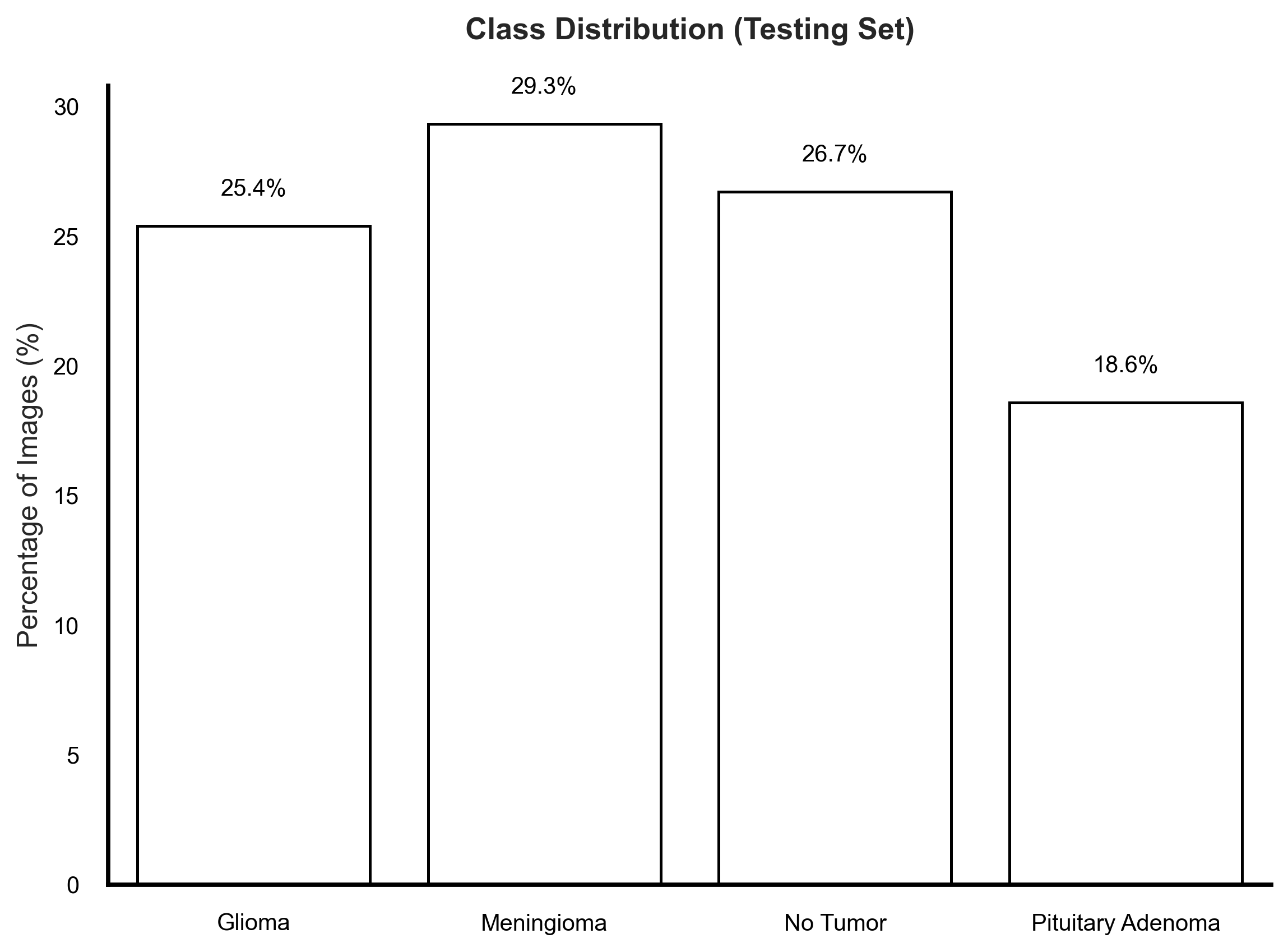
An analysis of class distribution in the provided training and testing sets revealed disparities that could influence model learning (Figure 2). Notably, while the training set showed a marked underrepresentation of the No Tumor class (13.7%), the testing set presented an imbalance in the opposite direction—with No Tumor cases forming a larger proportion than any single tumor category. More importantly, among the tumor classes, Pituitary Adenoma remained consistently underrepresented, particularly in the test set where it accounted for only 18.6% of images. In clinical machine learning applications, it is often more critical to maintain uniform representation among disease classes to ensure equitable sensitivity across diagnostic categories. Imbalanced datasets—even with mild disparities—can skew model learning dynamics, leading to suppressed recall for minority tumor types, which is undesirable in real-world neuro-oncological screening scenarios.
Figure 2: Training and testing set class distributions.
We also conducted a systematic review of the data augmentation strategy to ensure compatibility with medical imaging features (Figure 3). As demonstrated in the figure below, each original image underwent a series of transformations including random horizontal flips, affine transformations (rotation, shear), and brightness shifts. These augmentations were chosen to simulate common variability in scan acquisition while enhancing model robustness. To verify that diagnostic features—such as lesion shape, tumor boundary, and intensity profile—were not distorted, qualitative evaluations were performed across all tumor classes. No visible degradation or artificial signal was introduced by the applied transformations, and model performance remained stable across validation folds.
Figure 3: Example of augmentation strategies (flip, brightness, rotation) applied to glioma and meningioma samples.
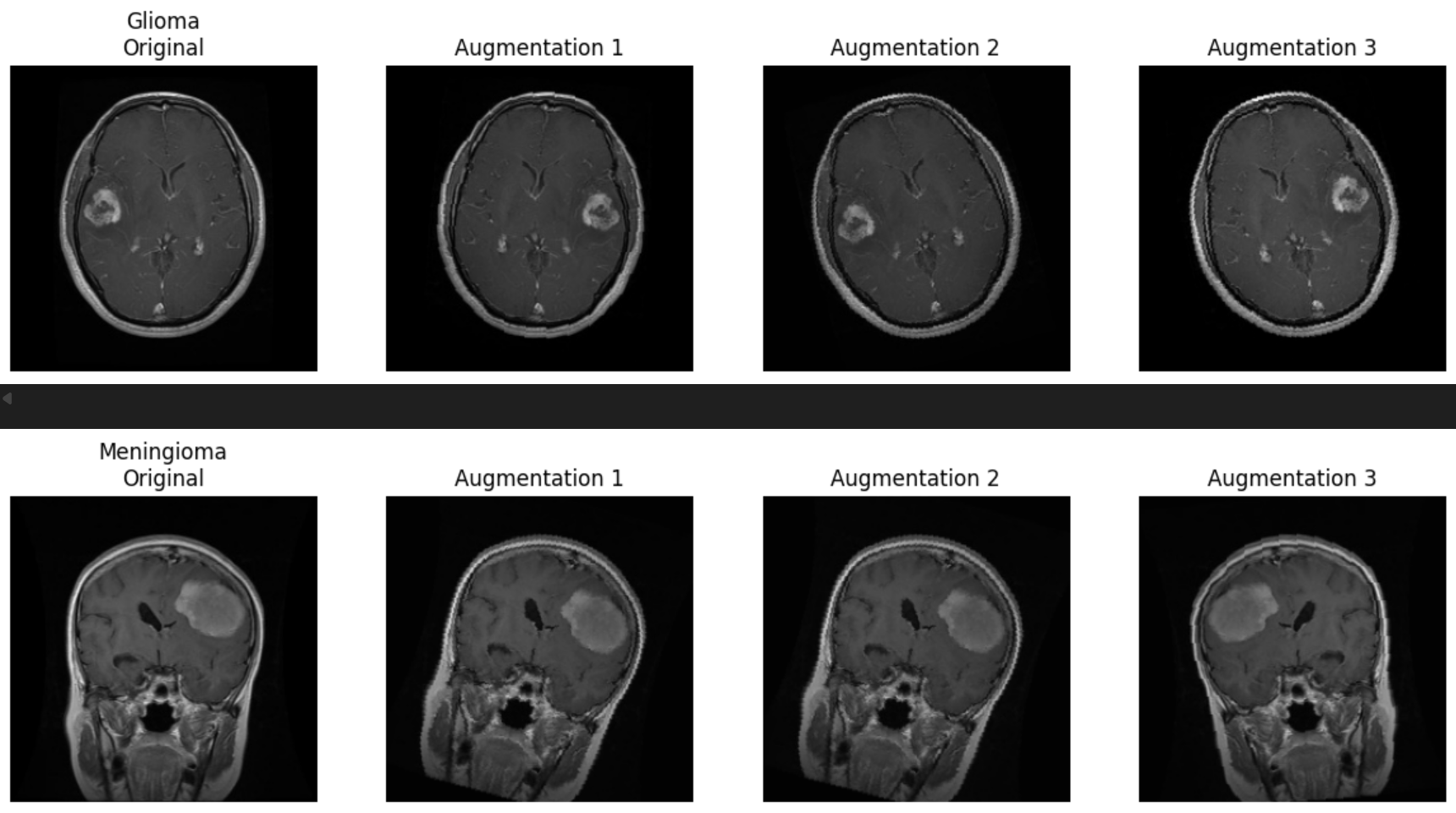
Augmentation can introduce bias if transformations inadvertently alter class-specific features or introduce artificial regularities not present in real data. In medical imaging, particular caution must be exercised with spatial and intensity manipulations to avoid creating anatomically implausible artifacts. Our validation confirmed that the augmentations preserved key tumor features, and thus contributed positively to generalization while maintaining clinical interpretability.
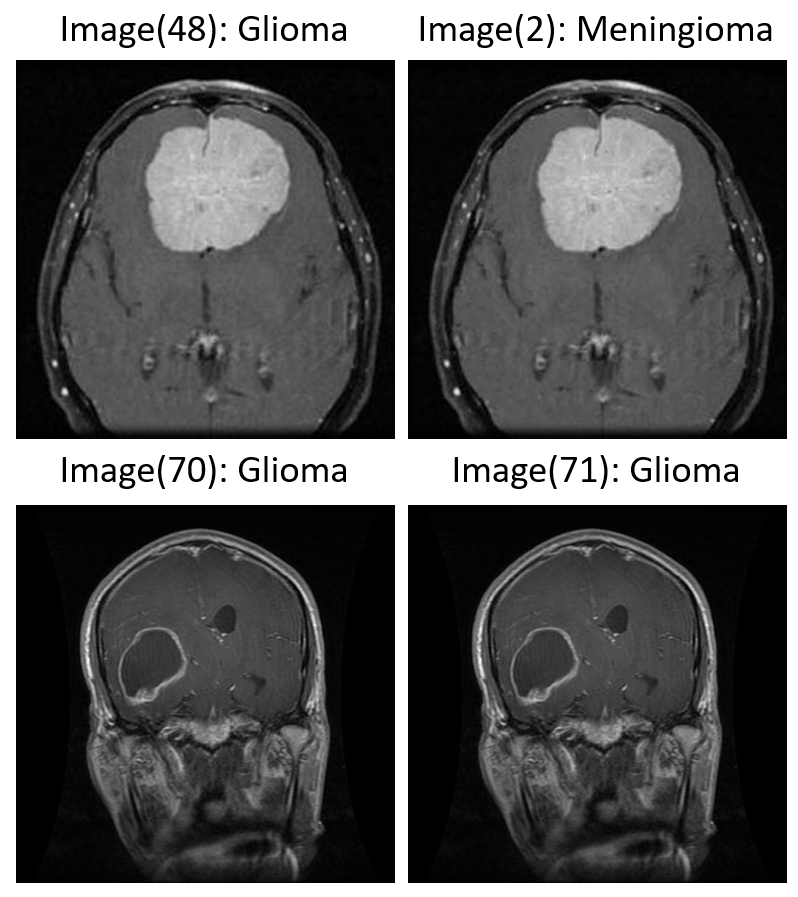
Following the augmentation assessment, we turned our attention to the integrity of the dataset itself—specifically the presence of duplicate images. During this phase of exploratory analysis, we identified a substantial number of duplicate instances, both within individual tumor classes (intra-class) (Figure 4: Image(70) & Image(71)) and, more concerningly, across different classes (inter-class) (Figure 4: Image(2) & Image(48)). In total, nearly 400 duplicates were detected, a subset of which appeared under conflicting class labels, suggesting possible mislabeling errors introduced during dataset curation.
The presence of duplicate images poses several challenges to model generalization. Intra-class duplicates can lead to data leakage between training and validation splits, inflating performance metrics and impairing real-world robustness. Inter-class duplicates are particularly detrimental, as they present the model with visually identical images assigned to different labels—confusing the learning process and eroding the consistency of decision boundaries. This is especially critical in clinical applications, where the reliability of model predictions must meet a high standard of diagnostic fidelity.
Examples of both intra- and inter-class duplication are shown below (Figure 4). Such anomalies necessitate rigorous preprocessing and data auditing pipelines prior to model training.
Figure 4: Examples of intra- and inter-class duplicates.
This project was built around a modular, reproducible machine learning pipeline designed for robust data management, validation, and interpretability—hallmarks of best practices in clinical AI development. Each pipeline stage is independent, parameterized, and traceable, promoting repeatability and enabling targeted debugging or enhancement without affecting the entire workflow.
Figure 5: End-to-End Pipeline for Data Preprocessing, Model Training, and Evaluation in Brain Tumor MRI Classification.
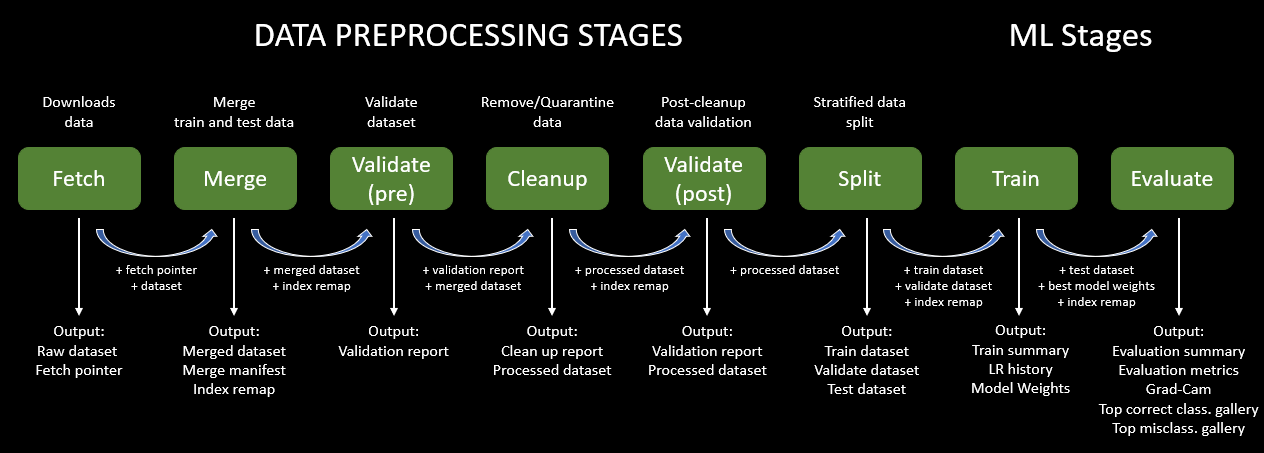
The fetch stage retrieves the original dataset and saves metadata pointers for traceability. This ensures that subsequent runs of the pipeline always reference the same dataset, a key aspect of reproducibility. Following this, the merge stage consolidates the provided Training and Testing folders into a single dataset, necessary for global inspection and class rebalance.
We introduced a validate (pre) stage to screen images for common issues: unreadable files, corrupted formats, and inconsistent dimensions. This early filtering step prevented training on malformed or ambiguous data, improving downstream performance. Next, the cleanup module employed perceptual hashing (pHash) to detect both exact and near-duplicate images. Intra-class duplicates were removed to prevent artificial inflation of performance metrics, and inter-class duplicates were excluded entirely due to their contradictory labels, which can confuse the model.
We followed up with validate (post) to confirm that the cleaned dataset retained all expected class labels and had no residual anomalies. Then, we performed a stratified split into training, validation, and test sets, with a specific emphasis on preserving class proportions across tumor types (glioma, meningioma, pituitary adenoma). This ensured that no subtype was overrepresented or excluded at any stage, supporting fair and balanced learning.
The resize stage standardized all images to 224x224 pixels using zero-padding to preserve anatomical structures. All images were normalized to have consistent intensity distributions. These transformations ensured compatibility with the ResNet architecture while maintaining critical diagnostic features.
Training was conducted using ResNet18, a well-established convolutional neural network architecture. It was selected for its balance of depth, generalization ability, and computational efficiency. Compared to larger models like ResNet50 or DenseNet121, ResNet18 offers faster training and inference—making it suitable for integration into lightweight diagnostic tools—while still maintaining high classification performance.
The final evaluate stage computes precision, recall, F1-score, and confusion matrices on the test set. These metrics provide quantitative insights into model performance across all diagnostic categories. To further ensure interpretability, we employed Grad-CAM (Gradient-weighted Class Activation Mapping) to visualize which regions of the input MRI most influenced the model's prediction. These saliency maps confirmed that the classifier was focusing on tumor-relevant anatomical regions rather than background or artifacts—an important step in validating the clinical relevance of the model's decision-making process.
Quantitative Performance
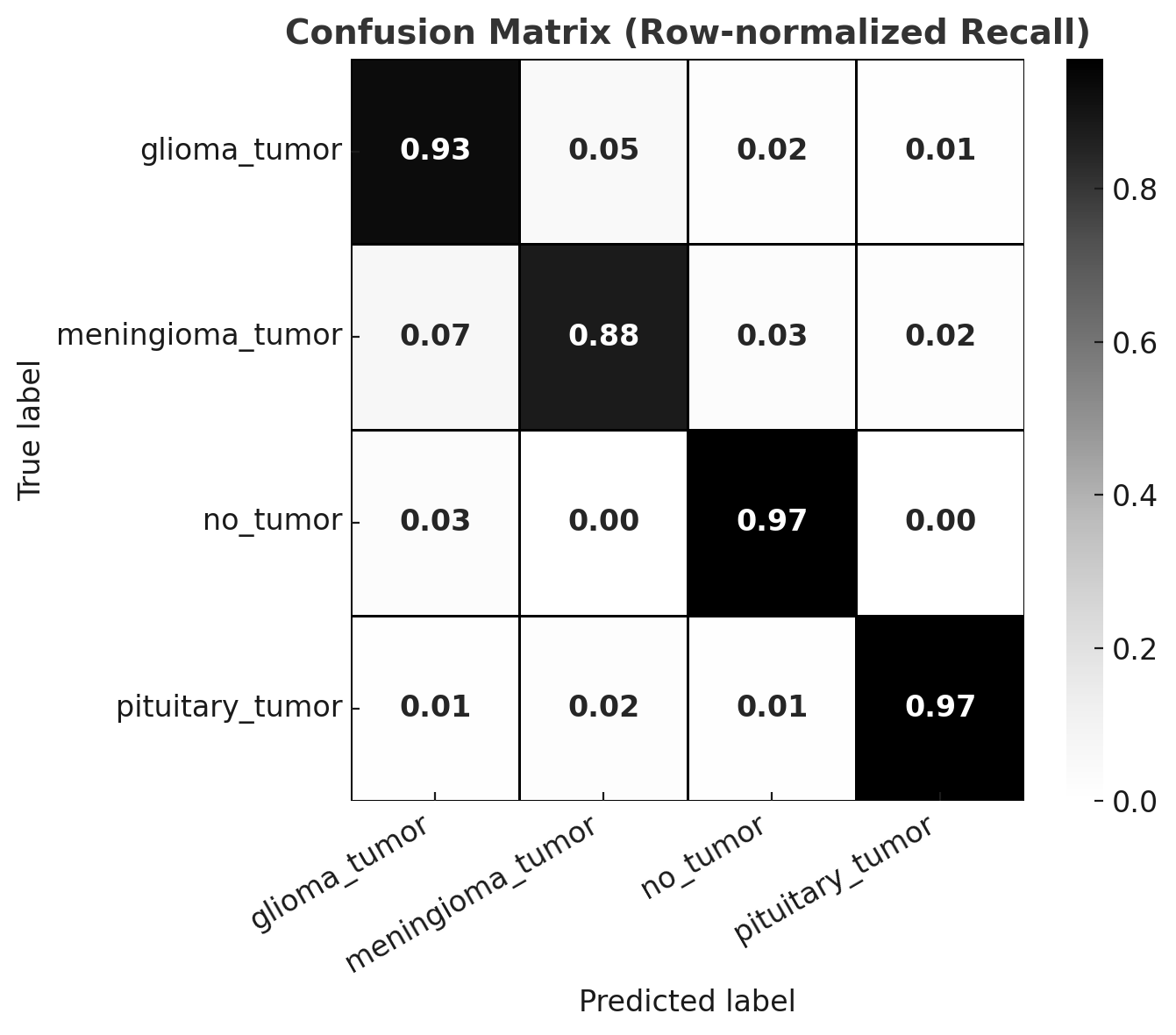
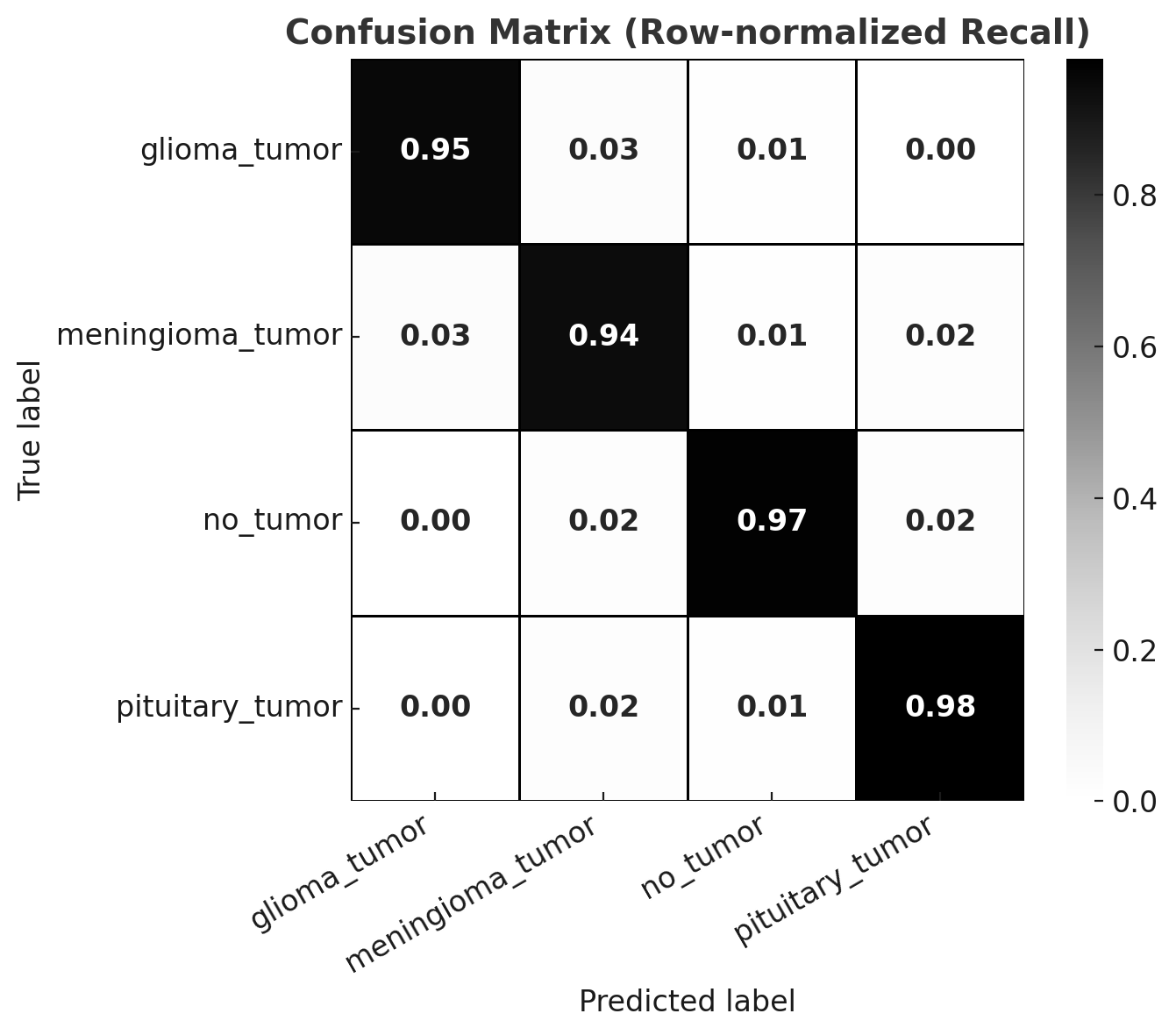
The classification framework was evaluated across four diagnostic categories: glioma, meningioma, pituitary adenoma, and no tumor. After removing exact duplicates (retaining the first occurrence), the model achieved an overall accuracy of 92.9% with a macro F1-score of 92.7% (Figure 6). When dataset cleaning was extended to also remove near-duplicates and cross-class duplicates, performance further improved to an accuracy of 95.8% and a macro F1-score of 95.5%(Figure 7).
Figure 6: Confusion matrix after exact duplicate removal.
| Class | Precision | Recall | F1-Score | Support |
|-----------------|-----------|--------|----------|---------|
| glioma_tumor | 0.916 | 0.927 | 0.921 | 177 |
| meningioma_tumor| 0.922 | 0.877 | 0.899 | 162 |
| no_tumor | 0.868 | 0.967 | 0.915 | 61 |
| pituitary_tumor | 0.976 | 0.970 | 0.973 | 166 |
| **Accuracy** | | | 0.929 | 566 |
| **Macro Avg** | 0.920 | 0.935 | 0.927 | 566 |
| **Weighted Avg**| 0.930 | 0.929 | 0.929 | 566 |Figure 7: Confusion matrix after comprehensive duplicate removal.
| Class | Precision | Recall | F1-Score | Support |
|-----------------|-----------|--------|----------|---------|
| glioma_tumor | 0.971 | 0.955 | 0.963 | 176 |
| meningioma_tumor| 0.938 | 0.938 | 0.938 | 162 |
| no_tumor | 0.922 | 0.967 | 0.944 | 61 |
| pituitary_tumor | 0.976 | 0.976 | 0.976 | 166 |
| **Accuracy** | | | 0.958 | 565 |
| **Macro Avg** | 0.952 | 0.959 | 0.955 | 565 |
| **Weighted Avg**| 0.958 | 0.958 | 0.958 | 565 |Impact of Dataset Curation
The improvement in performance highlights the critical role of dataset curation in medical AI. Duplicates—whether exact, near-identical, or cross-class—can artificially inflate model performance by leaking test information into the training set. This creates the illusion of high accuracy while undermining true generalization. Once duplicates were removed, the model exhibited more reliable class separation, particularly improving performance on meningiomas where cross-class duplicate leakage had previously confused the classifier. These findings reinforce the importance of validation pipelines that enforce image integrity, uniqueness, and class consistency (Roberts et al., Nature Medicine, 2021).
Correct Classifications
Grad-CAM visualizations of correctly classified cases confirm that the model focuses on regions consistent with radiological expectations. In these overlays, warmer colors (red and orange) highlight the areas where the network places the greatest emphasis during prediction, while cooler colors (blue) correspond to regions with minimal contribution. This distinction allows direct inspection of whether the model bases its decision on clinically relevant cues.
For gliomas, the heatmaps align with intra-axial lesions exhibiting infiltrative margins (Figure 8). Meningiomas are accurately identified at dural or peripheral attachment sites, consistent with their extra-axial presentation (Figure 9). Pituitary adenomas are localized to the sella turcica with concentrated red activation at the lesion boundaries (Figure 10). Finally, in no tumor cases, the activation maps remain diffuse or midline-focused without strong hotspots, consistent with normal anatomy (Figure 11). The correspondence between the model's attention and radiological landmarks indicates that the network is learning meaningful diagnostic features rather than relying on spurious correlations.
Figure 8: Glioma — original (A) vs. Grad-CAM (B), correct model prediction.
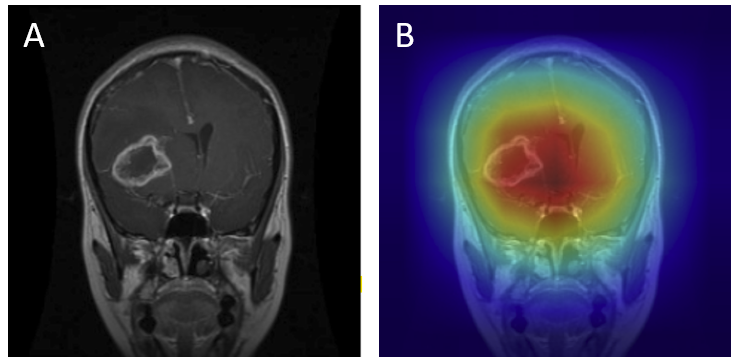
Figure 9: Meningioma — original (A) vs. Grad-CAM (B), correct model prediction.
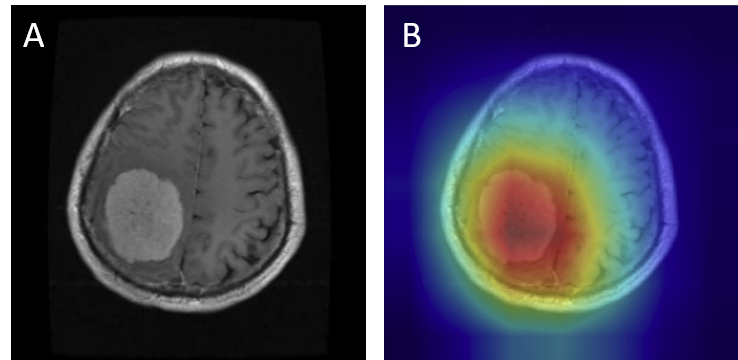
Figure 10: Pituitary Adenoma — original (A) vs. Grad-CAM (B), correct model prediction.
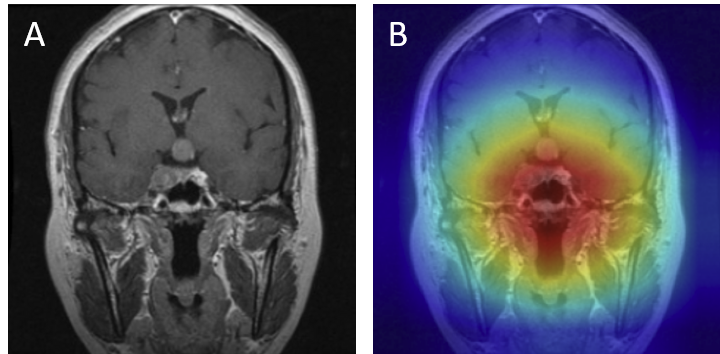
Figure 11: No tumor — original (A) vs. Grad-CAM (B), correct model prediction.
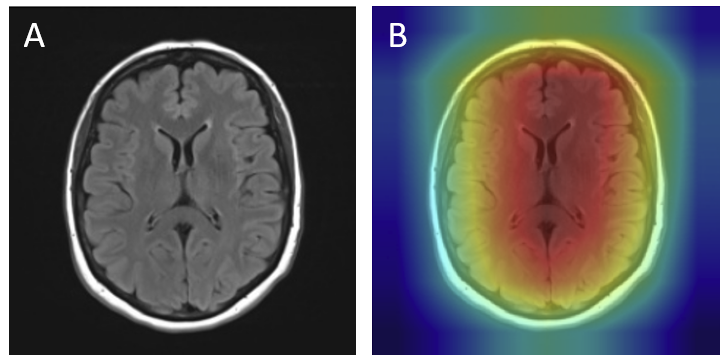
Analysis of Misclassifications
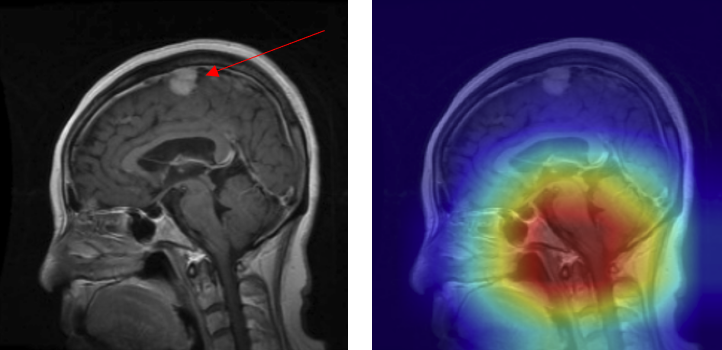
Although the model demonstrated high overall accuracy, systematic error analysis revealed several recurring failure modes. Examination of misclassified cases with Grad-CAM overlays provided critical insights into the underlying causes of these errors. In the figures presented below, red arrows denote the ground-truth lesion locations, allowing direct comparison between the true pathology and the regions emphasized by the model’s attention maps.
- Attention drift - Grad-CAMs sometimes highlight irrelevant regions such as skull edges or ventricles rather than the tumor mass (Figure 12B).
- Peripheral tumors - Lesions at the brain-skull interface, especially meningiomas, were occasionally misclassified as no tumor. Strong boundary contrast dominated the model's attention, while the actual lesion (red arrow) was ignored (Figure 13).
- Over-reliance on structural cues - Some no tumor cases were misclassified because the model focused on midline or background features, mistaking normal anatomy for pathology (Figure 14).
- Contrast variability - Differences in MRI acquisition or contrast sometimes produced tumor appearances resembling another class. For example, homogeneous gliomas were misclassified as meningiomas (Figure 15).
- Mislocalized attention - In some cases, the model predicted the presence of a tumor but focused on the wrong anatomical region. For example, a meningioma at the top of the brain (arrow) was misclassified as a pituitary adenoma because the Grad-CAM highlighted the sellar region instead of the true lesion (Figure 16).
Figure 12: Misclassification — meningioma as pituitary: (A) original with red arrow marking lesion, (B) Grad-CAM showing off-target attention.
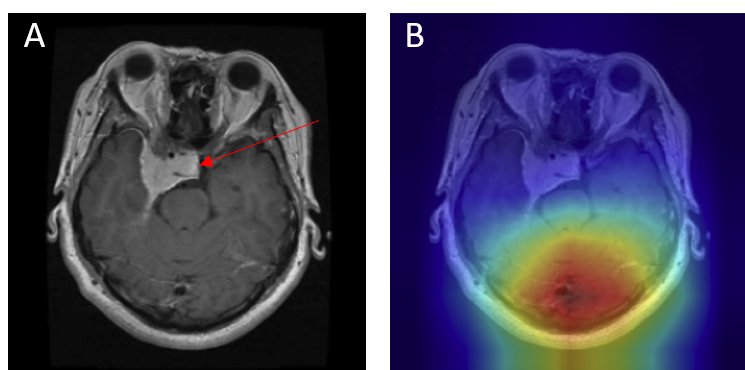
Figure 13: Meningioma at brain-skull interface misclassified as no_tumor (false negative): (A) original with lesion marked by arrow, (B) Grad-CAM showing edge-dominated focus.
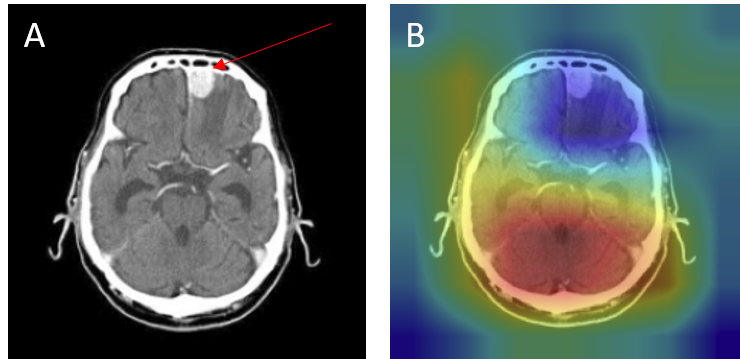
Figure 14: No tumor case misclassified as tumor — (A) original with arrow showing absence of lesion, (B) Grad-CAM focusing incorrectly on midline/background structures.
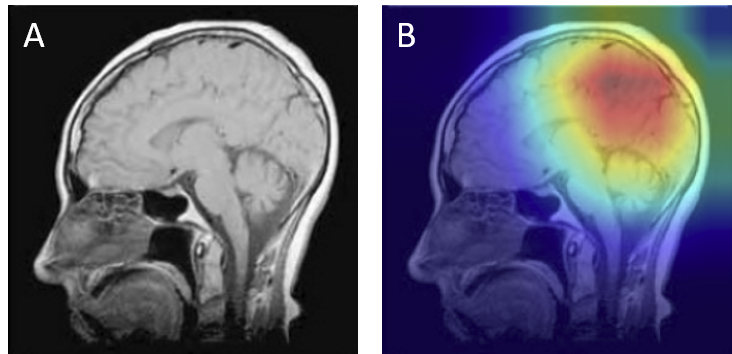
Figure 15: Acquisition contrast shift — glioma misclassified as meningioma: (A) original with lesion marked, (B) Grad-CAM showing attention skewed by contrast pattern.
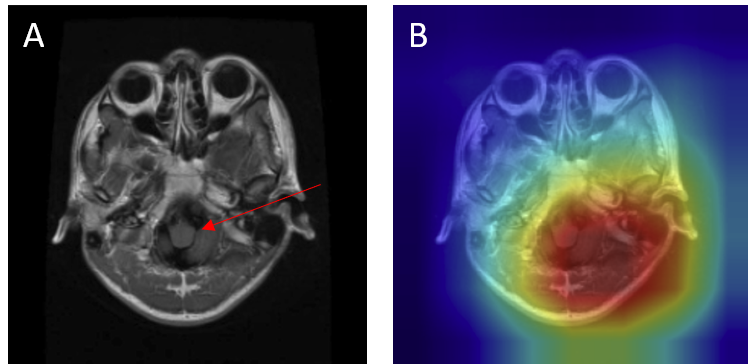
Figure 16: Mislocalized attention — meningioma (true) misclassified as pituitary adenoma with 0.99 confidence: (A) original with arrow marking lesion, (B) Grad-CAM focusing incorrectly on the sellar region.
These misclassifications demonstrate that although the model achieves strong overall performance, it can still base predictions on spurious cues (edges, background, or unrelated anatomy) rather than the lesion itself. Addressing these failure modes will require improved preprocessing (e.g., skull-stripping, intensity normalization), data augmentation strategies to disrupt shortcut reliance, and post-hoc calibration to temper overconfident errors. For clinical translation, such measures are crucial to ensure that model focus consistently aligns with the pathology, thereby supporting safe and trustworthy decision support in diagnostic settings.
Clinical Implications
Achieving accuracy above 95% with balanced per-class performance demonstrates the strong potential of deep learning for brain tumor classification. However, translation to real-world diagnostic practice requires robustness across imaging protocols, scanner variations, and populations not represented in the training set. Moreover, interpretability is crucial: clinicians must trust that the model bases decisions on tumor regions rather than artifacts or anatomical edges. Regulatory frameworks such as the FDA and European MDR emphasize reproducibility, transparency, and error calibration as prerequisites for clinical adoption. The results presented here therefore demonstrate both the promise of AI-assisted tumor classification and the ongoing challenges in ensuring safe, equitable, and generalizable performance.
This study demonstrates the feasibility of constructing a modular, reproducible machine learning pipeline for automated brain tumor classification from MRI scans. By integrating systematic preprocessing, rigorous validation, duplicate removal, and interpretable model evaluation, the pipeline addresses many of the key concerns in the deployment of AI for medical imaging, including data quality, reproducibility, and trustworthiness of predictions.
Pipeline and Reproducibility
The pipeline adopted here emphasizes traceability and repeatability as core principles. Each stage—from dataset fetching and merging, to validation, cleanup, resizing, splitting, training, and evaluation—was modularized and parameterized. This approach ensures that experiments can be rerun under identical conditions, thereby enhancing reproducibility, which is a cornerstone of scientific rigor and a regulatory expectation in clinical AI development (Sullivan et al., 2019; Roberts et al., 2021). Moreover, automated validation routines (e.g., detection of corrupted images, label inconsistencies, and duplicate samples) directly improved the reliability of the dataset, reducing the risk of inflated performance estimates caused by data leakage.
Impact of Data Quality
Our findings clearly illustrate how poor dataset curation can distort model evaluation. When near-duplicates and cross-class duplicates were present, performance metrics appeared deceptively high, but the model failed to generalize reliably. After comprehensive duplicate removal, accuracy improved to 95.8% with a macro F1-score of 95.5%, highlighting that robust curation not only prevents inflated benchmarks but also produces models that are more representative of true diagnostic capability. This aligns with broader observations in medical AI that “garbage in, garbage out” holds especially true for sensitive clinical applications (Oakden-Rayner, 2020).
Interpretability and Error Analysis
Visual inspection of Grad-CAM overlays revealed that correct classifications generally aligned with radiological expectations: gliomas were highlighted in intra-axial regions, meningiomas at dural attachments, and pituitary adenomas within the sellar region. Misclassifications, however, uncovered important failure modes, including attention drift to ventricles or skull boundaries, over-reliance on structural cues in no-tumor cases, contrast-driven confusion between gliomas and meningiomas, and mislocalized attention where predictions were driven by the wrong anatomical region. These findings illustrate the dual value of Grad-CAM: not only as an interpretability tool, but also as a means of diagnosing model weaknesses and identifying shortcut learning behaviors (Selvaraju et al., 2017).
Clinical Context
Brain tumors remain a major cause of morbidity and mortality worldwide, with glioblastoma in particular associated with a 5-year survival rate below 5% (Ostrom et al., 2022). MRI is the gold standard for diagnosis, but manual interpretation is time-consuming and subject to inter-observer variability. In this context, AI-based systems capable of achieving accuracies above 95% with balanced class-level performance represent a transformative opportunity. Such models could assist radiologists in triage, provide second opinions in resource-limited settings, and improve the consistency of tumor subtype recognition. However, translation into clinical workflows requires robust calibration of model confidence, external validation on multi-center datasets, and assurance that predictions are not driven by spurious image features.
Broader Implications
The results of this project align with growing evidence that deep learning, when applied to curated and well-validated datasets, can reach or surpass human-level diagnostic accuracy in certain tasks (Esteva et al., 2017; Lundervold & Lundervold, 2019). Nonetheless, this work also highlights the limitations of current methods. Without rigorous preprocessing and validation pipelines, models may exploit dataset artifacts, undermining their reliability in real-world applications. Furthermore, while convolutional neural networks such as ResNet18 provide strong baselines, future work should explore architectures tailored to volumetric data (e.g., 3D CNNs or transformers) and incorporate multimodal information such as clinical variables or genomic markers for a more holistic diagnostic framework.
Summary
In sum, this project demonstrates the dual importance of technical rigor and clinical relevance in AI for neuro-oncology. A carefully designed pipeline not only improved model performance but also ensured that results are reproducible, interpretable, and clinically meaningful. These characteristics will be essential for the future adoption of AI-based diagnostic tools in routine practice, where patient safety and reliability remain paramount.
References
- Bakas S. et al. (2018). Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BraTS challenge. arXiv:1811.02629.
- Ellingson B.M. et al. (2015). Consensus recommendations for a standardized Brain Tumor Imaging Protocol in clinical trials. Neuro-Oncology, 17(9), 1188–1198.
- Esteva A. et al. (2017). Dermatologist-level classification of skin cancer with deep neural networks. Nature, 542, 115–118.
- Gevaert O. et al. (2016). Radiogenomics in glioblastoma: A review. Clinical Cancer Research, 22(2), 323–329.
- Goldbrunner R. et al. (2021). EANO guideline on the diagnosis and management of meningiomas. Neuro-Oncology, 23(11), 1821–1834.
- Louis D.N. et al. (2021). The 2021 WHO Classification of Tumors of the Central Nervous System. Acta Neuropathologica, 142, 1–24.
- Lundervold A.S., Lundervold A. (2019). An overview of deep learning in medical imaging focusing on MRI. IEEE Signal Processing Magazine, 36(5), 48–69.
- Melmed S. (2020). Pituitary-tumor endocrinopathies. New England Journal of Medicine, 382, 937–950.
- Menze B.H. et al. (2015). The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Transactions on Medical Imaging, 34(10), 1993–2024.
- Oakden-Rayner L. (2020). Exploring the false hope of current approaches to explainable AI in health care. arXiv:2009.09600.
- Ostrom Q.T. et al. (2022). CBTRUS Statistical Report: Primary brain and other central nervous system tumors diagnosed in the United States. Neuro-Oncology, 24(S5), v1–v95.
- Roberts M. et al. (2021). Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans. Nature Medicine, 27, 187–191.
- Selvaraju R.R. et al. (2017). Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Proceedings of ICCV, 618–626.
- Sullivan D.C. et al. (2019). Quantitative imaging biomarkers: A call for collaboration on data sharing. Nature, 567, 151–153.
- Weller M. et al. (2015). EANO guideline for the diagnosis and treatment of adult astrocytic and oligodendroglial gliomas. Lancet Oncology, 16(9), e395–e403.
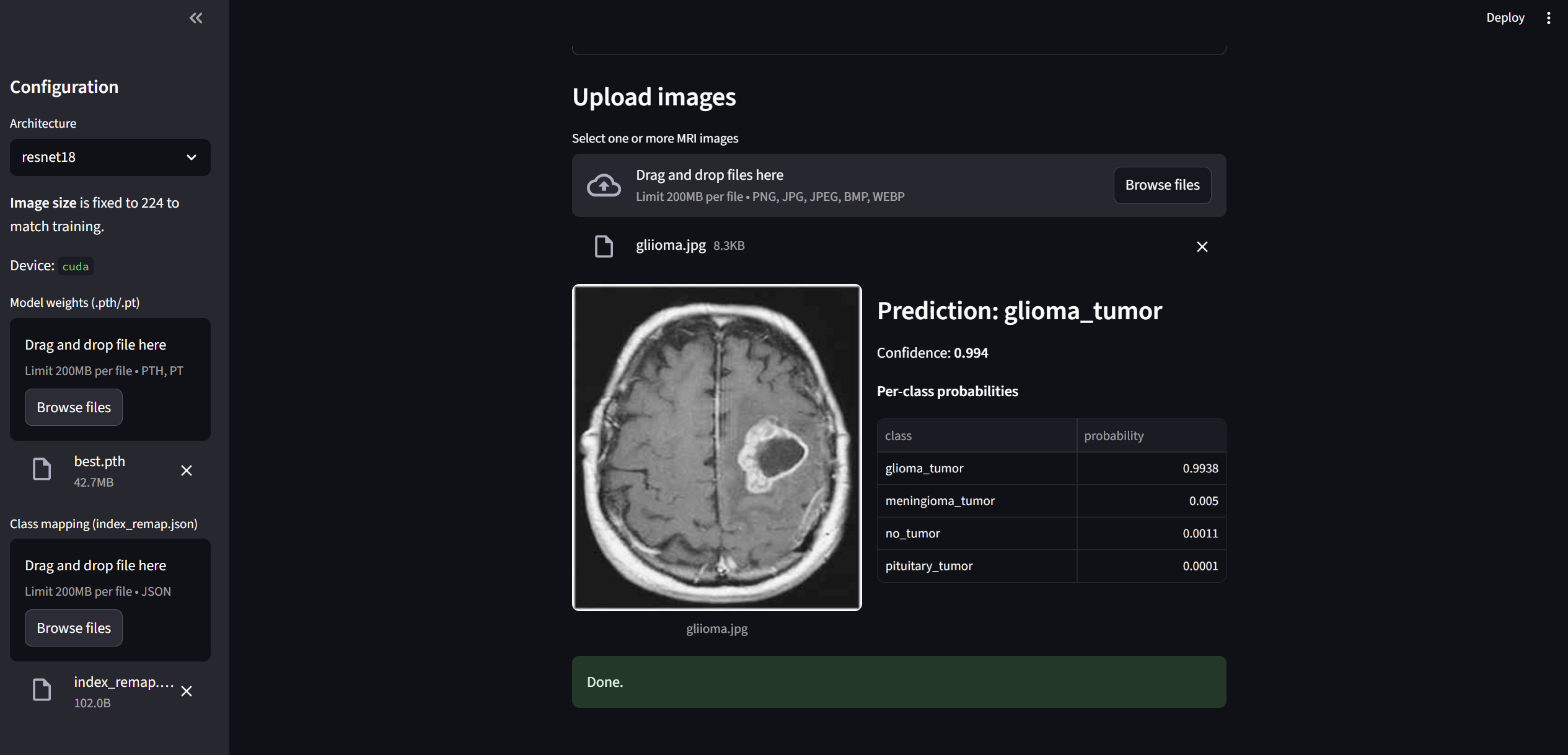
This project includes a deployable Streamlit application for interactive inference. The app lets you drag-and-drop one or more MRI images and returns a prediction for each image with **per-class probabilities** across four categories: glioma_tumor, meningioma_tumor, pituitary_tumor, and no_tumor. Each uploaded image is displayed alongside a table of class probabilities (see example below). Images are automatically resized/padded to 224×224 to match the training configuration, ensuring consistent preprocessing at inference time.
- Model selection & device: Choose a ResNet architecture (default: ResNet18) and the app will run on the best available device (CPU or CUDA) detected at startup.
- Model weights: Load your trained weights (
.pth/.pt). Important: weights must correspond to the selected architecture (e.g., ResNet18 weights for ResNet18) to ensure correct performance. - Class mapping: Upload the accompanying
index_remap.jsonso predicted indices map to human-readable labels in the correct order. Without this, class names may be misaligned. - Batch uploads: Drag-and-drop multiple images; the app processes them sequentially and renders a prediction card for each file.
- Extensible backbones: The UI is compatible with other ResNet variants (e.g., ResNet34/50) provided you upload the matching trained weights and the correct
index_remap.json.
Typical usage flow: select architecture → load best.pth (or other checkpoint) → load
index_remap.json → drop MRI images → review predictions and probability tables. This design makes the app suitable both for quick demos and for
validating model behavior on new scans prior to any clinical integration.
Notes: The app performs no PHI storage and processes images in-memory during a session.
For production use, consider model calibration (temperature scaling), audit logging, and role-based access,
and ensure your deployment complies with local information governance and medical device regulations.
Important: This application is not a clinical diagnostic tool. It was developed
as a showcase for this project to demonstrate the trained model and pipeline. While the
predictions reflect the behavior of the trained classifier, the tool is unsuitable for clinical decision-making
and should not be used in medical settings.